Testen Sie IHR Unternehmen in Minuten
Erstellen Sie Ihr Konto und starten Sie Ihren KI-Chatbot in wenigen Minuten. Vollständig anpassbar, keine Programmierung erforderlich - beginnen Sie sofort, Ihre Kunden zu begeistern!
Fertig in wenigen Minuten
Keine Programmierkenntnisse erforderlich
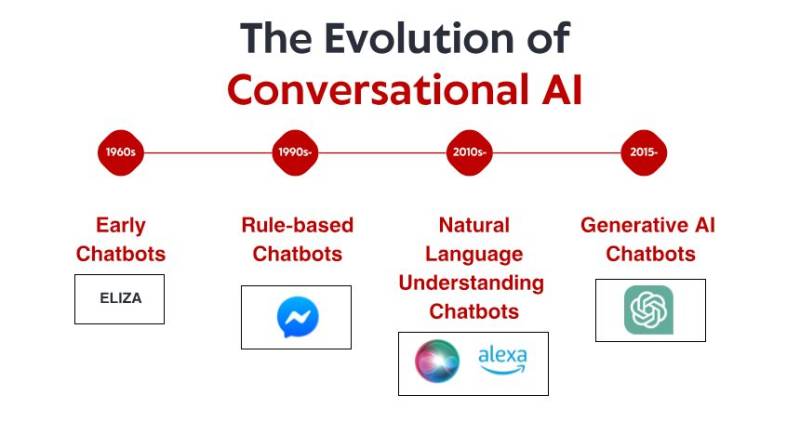
Die bescheidenen Anfänge: Frühe regelbasierte Systeme
Die Geschichte der Konversations-KI beginnt in den 1960er Jahren, lange bevor Smartphones und Sprachassistenten zum Alltag gehörten. In einem kleinen Labor am MIT entwickelte der Informatiker Joseph Weizenbaum den ersten Chatbot, den viele als solchen bezeichnen: ELIZA. ELIZA sollte einen rogerianischen Psychotherapeuten simulieren und arbeitete mit einfachen Mustererkennungs- und Substitutionsregeln. Wenn ein Nutzer „Ich bin traurig“ eintippte, antwortete ELIZA möglicherweise mit „Warum bist du traurig?“ – und erzeugte so die Illusion von Verständnis, indem er die Aussagen in Fragen umformulierte.
Was ELIZA so bemerkenswert machte, war nicht seine technische Raffinesse – nach heutigen Maßstäben war das Programm unglaublich einfach. Es war vielmehr die tiefgreifende Wirkung, die es auf die Nutzer hatte. Obwohl sie wussten, dass sie mit einem Computerprogramm sprachen, das sie nicht wirklich verstand, bauten viele Menschen eine emotionale Verbindung zu ELIZA auf und teilten tiefgründige persönliche Gedanken und Gefühle. Dieses Phänomen, das Weizenbaum selbst beunruhigend fand, enthüllte etwas Grundlegendes über die menschliche Psychologie und unsere Bereitschaft, selbst einfachste Gesprächsschnittstellen zu vermenschlichen.
In den 1970er und 1980er Jahren folgten regelbasierte Chatbots ELIZAs Vorlage, wurden jedoch schrittweise verbessert. Programme wie PARRY (das einen paranoiden Schizophrenen simulierte) und RACTER (Autor des Buches „Der Bart des Polizisten ist halb konstruiert“) blieben dem regelbasierten Paradigma treu – mit vordefinierten Mustern, Schlüsselwortabgleich und vorgefertigten Antworten.
Diese frühen Systeme hatten gravierende Einschränkungen. Sie konnten weder Sprache verstehen, aus Interaktionen lernen noch sich an unerwartete Eingaben anpassen. Ihr Wissen beschränkte sich auf die Regeln, die ihre Programmierer explizit definiert hatten. Sobald Nutzer diese Grenzen zwangsläufig überschritten, zerbrach die Illusion von Intelligenz schnell und enthüllte die zugrundeliegende mechanische Natur. Trotz dieser Einschränkungen bildeten diese bahnbrechenden Systeme die Grundlage für alle zukünftigen Konversations-KIs.
Was ELIZA so bemerkenswert machte, war nicht seine technische Raffinesse – nach heutigen Maßstäben war das Programm unglaublich einfach. Es war vielmehr die tiefgreifende Wirkung, die es auf die Nutzer hatte. Obwohl sie wussten, dass sie mit einem Computerprogramm sprachen, das sie nicht wirklich verstand, bauten viele Menschen eine emotionale Verbindung zu ELIZA auf und teilten tiefgründige persönliche Gedanken und Gefühle. Dieses Phänomen, das Weizenbaum selbst beunruhigend fand, enthüllte etwas Grundlegendes über die menschliche Psychologie und unsere Bereitschaft, selbst einfachste Gesprächsschnittstellen zu vermenschlichen.
In den 1970er und 1980er Jahren folgten regelbasierte Chatbots ELIZAs Vorlage, wurden jedoch schrittweise verbessert. Programme wie PARRY (das einen paranoiden Schizophrenen simulierte) und RACTER (Autor des Buches „Der Bart des Polizisten ist halb konstruiert“) blieben dem regelbasierten Paradigma treu – mit vordefinierten Mustern, Schlüsselwortabgleich und vorgefertigten Antworten.
Diese frühen Systeme hatten gravierende Einschränkungen. Sie konnten weder Sprache verstehen, aus Interaktionen lernen noch sich an unerwartete Eingaben anpassen. Ihr Wissen beschränkte sich auf die Regeln, die ihre Programmierer explizit definiert hatten. Sobald Nutzer diese Grenzen zwangsläufig überschritten, zerbrach die Illusion von Intelligenz schnell und enthüllte die zugrundeliegende mechanische Natur. Trotz dieser Einschränkungen bildeten diese bahnbrechenden Systeme die Grundlage für alle zukünftigen Konversations-KIs.
Die Wissensrevolution: Expertensysteme und strukturierte Informationen
In den 1980er und frühen 1990er Jahren entstanden Expertensysteme – KI-Programme, die komplexe Probleme lösen sollten, indem sie die Entscheidungskompetenz menschlicher Experten in bestimmten Bereichen nachahmten. Obwohl diese Systeme nicht primär für Konversation konzipiert waren, stellten sie einen wichtigen Entwicklungsschritt für die Konversations-KI dar, indem sie eine komplexere Wissensrepräsentation einführten.
Expertensysteme wie MYCIN (zur Diagnose bakterieller Infektionen) und DENDRAL (zur Identifizierung chemischer Verbindungen) organisierten Informationen in strukturierten Wissensdatenbanken und nutzten Inferenzmaschinen, um Schlussfolgerungen zu ziehen. Angewandt auf Konversationsschnittstellen ermöglichte dieser Ansatz Chatbots, über einfaches Mustervergleichen hinauszugehen und – zumindest in engen Bereichen – logisches Denken zu entwickeln.
Unternehmen begannen, praktische Anwendungen wie automatisierte Kundenservicesysteme mit dieser Technologie zu implementieren. Diese Systeme nutzten typischerweise Entscheidungsbäume und menübasierte Interaktionen anstelle freier Konversation, stellten aber frühe Versuche dar, Interaktionen zu automatisieren, die zuvor menschliches Eingreifen erforderten.
Die Einschränkungen blieben erheblich. Diese Systeme waren anfällig und konnten unerwartete Eingaben nicht zuverlässig verarbeiten. Sie erforderten enormen Aufwand von Wissensingenieuren, um Informationen und Regeln manuell zu kodieren. Und vielleicht am wichtigsten: Sie konnten natürliche Sprache in ihrer ganzen Komplexität und Mehrdeutigkeit noch nicht wirklich verstehen.
Dennoch etablierte diese Ära wichtige Konzepte, die später für die moderne Konversations-KI entscheidend werden sollten: strukturierte Wissensrepräsentation, logische Schlussfolgerung und Domänenspezialisierung. Die Bühne war bereit für einen Paradigmenwechsel, auch wenn die Technologie noch nicht so weit war.
Expertensysteme wie MYCIN (zur Diagnose bakterieller Infektionen) und DENDRAL (zur Identifizierung chemischer Verbindungen) organisierten Informationen in strukturierten Wissensdatenbanken und nutzten Inferenzmaschinen, um Schlussfolgerungen zu ziehen. Angewandt auf Konversationsschnittstellen ermöglichte dieser Ansatz Chatbots, über einfaches Mustervergleichen hinauszugehen und – zumindest in engen Bereichen – logisches Denken zu entwickeln.
Unternehmen begannen, praktische Anwendungen wie automatisierte Kundenservicesysteme mit dieser Technologie zu implementieren. Diese Systeme nutzten typischerweise Entscheidungsbäume und menübasierte Interaktionen anstelle freier Konversation, stellten aber frühe Versuche dar, Interaktionen zu automatisieren, die zuvor menschliches Eingreifen erforderten.
Die Einschränkungen blieben erheblich. Diese Systeme waren anfällig und konnten unerwartete Eingaben nicht zuverlässig verarbeiten. Sie erforderten enormen Aufwand von Wissensingenieuren, um Informationen und Regeln manuell zu kodieren. Und vielleicht am wichtigsten: Sie konnten natürliche Sprache in ihrer ganzen Komplexität und Mehrdeutigkeit noch nicht wirklich verstehen.
Dennoch etablierte diese Ära wichtige Konzepte, die später für die moderne Konversations-KI entscheidend werden sollten: strukturierte Wissensrepräsentation, logische Schlussfolgerung und Domänenspezialisierung. Die Bühne war bereit für einen Paradigmenwechsel, auch wenn die Technologie noch nicht so weit war.
Natürliches Sprachverständnis: Der Durchbruch in der Computerlinguistik
In den späten 1990er und frühen 2000er Jahren rückten die Verarbeitung natürlicher Sprache (NLP) und die Computerlinguistik zunehmend in den Fokus. Anstatt Regeln für jede mögliche Interaktion manuell zu programmieren, begannen Forscher mit der Entwicklung statistischer Methoden, die Computern helfen sollten, die inhärenten Muster der menschlichen Sprache zu verstehen.
Dieser Wandel wurde durch mehrere Faktoren ermöglicht: steigende Rechenleistung, bessere Algorithmen und vor allem die Verfügbarkeit großer Textkorpora, die analysiert werden konnten, um sprachliche Muster zu identifizieren. Systeme begannen, Techniken wie diese zu integrieren:
Part-of-Speech-Tagging: Identifizierung, ob Wörter als Substantive, Verben, Adjektive usw. fungieren.
Named-Entity-Erkennung: Erkennung und Klassifizierung von Eigennamen (Personen, Organisationen, Orte).
Sentimentanalyse: Bestimmung des emotionalen Tons von Texten.
Parsing: Analyse der Satzstruktur, um grammatikalische Beziehungen zwischen Wörtern zu identifizieren.
Ein bemerkenswerter Durchbruch kam mit IBMs Watson, der menschliche Champions in der Quizshow Jeopardy! besiegte. im Jahr 2011. Obwohl Watson kein Konversationssystem im eigentlichen Sinne war, zeigte er beispiellose Fähigkeiten, Fragen in natürlicher Sprache zu verstehen, riesige Wissensspeicher zu durchsuchen und Antworten zu formulieren – Fähigkeiten, die sich für die nächste Generation von Chatbots als unverzichtbar erweisen sollten.
Kommerzielle Anwendungen folgten bald. Apples Siri kam 2011 auf den Markt und machte Konversationsschnittstellen für den Mainstream zugänglich. Obwohl nach heutigen Maßstäben eingeschränkt, stellte Siri einen bedeutenden Fortschritt dar, um KI-Assistenten für Alltagsnutzer zugänglich zu machen. Microsofts Cortana, Googles Assistant und Amazons Alexa folgten und trieben den Stand der Technik im Bereich der verbraucherorientierten Konversations-KI voran.
Trotz dieser Fortschritte hatten die Systeme dieser Ära noch immer Probleme mit Kontext, gesundem Menschenverstand und der Generierung wirklich natürlich klingender Antworten. Sie waren ausgefeilter als ihre regelbasierten Vorgänger, blieben aber in ihrem Verständnis von Sprache und der Welt grundsätzlich begrenzt.
Dieser Wandel wurde durch mehrere Faktoren ermöglicht: steigende Rechenleistung, bessere Algorithmen und vor allem die Verfügbarkeit großer Textkorpora, die analysiert werden konnten, um sprachliche Muster zu identifizieren. Systeme begannen, Techniken wie diese zu integrieren:
Part-of-Speech-Tagging: Identifizierung, ob Wörter als Substantive, Verben, Adjektive usw. fungieren.
Named-Entity-Erkennung: Erkennung und Klassifizierung von Eigennamen (Personen, Organisationen, Orte).
Sentimentanalyse: Bestimmung des emotionalen Tons von Texten.
Parsing: Analyse der Satzstruktur, um grammatikalische Beziehungen zwischen Wörtern zu identifizieren.
Ein bemerkenswerter Durchbruch kam mit IBMs Watson, der menschliche Champions in der Quizshow Jeopardy! besiegte. im Jahr 2011. Obwohl Watson kein Konversationssystem im eigentlichen Sinne war, zeigte er beispiellose Fähigkeiten, Fragen in natürlicher Sprache zu verstehen, riesige Wissensspeicher zu durchsuchen und Antworten zu formulieren – Fähigkeiten, die sich für die nächste Generation von Chatbots als unverzichtbar erweisen sollten.
Kommerzielle Anwendungen folgten bald. Apples Siri kam 2011 auf den Markt und machte Konversationsschnittstellen für den Mainstream zugänglich. Obwohl nach heutigen Maßstäben eingeschränkt, stellte Siri einen bedeutenden Fortschritt dar, um KI-Assistenten für Alltagsnutzer zugänglich zu machen. Microsofts Cortana, Googles Assistant und Amazons Alexa folgten und trieben den Stand der Technik im Bereich der verbraucherorientierten Konversations-KI voran.
Trotz dieser Fortschritte hatten die Systeme dieser Ära noch immer Probleme mit Kontext, gesundem Menschenverstand und der Generierung wirklich natürlich klingender Antworten. Sie waren ausgefeilter als ihre regelbasierten Vorgänger, blieben aber in ihrem Verständnis von Sprache und der Welt grundsätzlich begrenzt.
Maschinelles Lernen und der datengesteuerte Ansatz
Mitte der 2010er Jahre kam es zu einem weiteren Paradigmenwechsel in der Konversations-KI, als maschinelles Lernen in der breiten Öffentlichkeit Einzug hielt. Anstatt sich auf handgefertigte Regeln oder begrenzte statistische Modelle zu verlassen, begannen Ingenieure, Systeme zu entwickeln, die Muster direkt aus Daten – und zwar aus großen Mengen – lernen konnten.
In dieser Ära etablierten sich die Intent-Klassifizierung und die Entitätsextraktion als Kernkomponenten der Konversationsarchitektur. Stellte ein Nutzer eine Anfrage, führte das System Folgendes durch:
Klassifizierung der Gesamtintention (z. B. Flug buchen, Wetter prüfen, Musik abspielen)
Extrahierung relevanter Entitäten (z. B. Orte, Daten, Songtitel)
Zuordnung dieser zu spezifischen Aktionen oder Antworten
Die Einführung der Messenger-Plattform von Facebook (heute Meta) im Jahr 2016 ermöglichte es Entwicklern, Chatbots zu erstellen, die Millionen von Nutzern erreichen konnten, was eine Welle kommerziellen Interesses auslöste. Viele Unternehmen implementierten Chatbots schnell, die Ergebnisse waren jedoch gemischt. Frühe kommerzielle Implementierungen frustrierten die Nutzer oft aufgrund mangelnden Verständnisses und starrer Konversationsabläufe.
Auch die technische Architektur von Konversationssystemen entwickelte sich in dieser Zeit weiter. Der typische Ansatz umfasste eine Pipeline spezialisierter Komponenten:
Automatische Spracherkennung (für Sprachschnittstellen)
Natürliches Sprachverständnis
Dialogmanagement
Natürliche Sprachgenerierung
Text-to-Speech (für Sprachschnittstellen)
Jede Komponente konnte separat optimiert werden, was schrittweise Verbesserungen ermöglichte. Diese Pipeline-Architekturen litten jedoch manchmal unter Fehlerfortpflanzung – Fehler in frühen Phasen breiteten sich kaskadierend im gesamten System aus.
Obwohl Maschinelles Lernen die Fähigkeiten deutlich verbesserte, hatten die Systeme immer noch Schwierigkeiten, den Kontext über lange Gespräche hinweg aufrechtzuerhalten, implizite Informationen zu verstehen und wirklich vielfältige und natürliche Antworten zu generieren. Der nächste Durchbruch würde einen radikaleren Ansatz erfordern.
In dieser Ära etablierten sich die Intent-Klassifizierung und die Entitätsextraktion als Kernkomponenten der Konversationsarchitektur. Stellte ein Nutzer eine Anfrage, führte das System Folgendes durch:
Klassifizierung der Gesamtintention (z. B. Flug buchen, Wetter prüfen, Musik abspielen)
Extrahierung relevanter Entitäten (z. B. Orte, Daten, Songtitel)
Zuordnung dieser zu spezifischen Aktionen oder Antworten
Die Einführung der Messenger-Plattform von Facebook (heute Meta) im Jahr 2016 ermöglichte es Entwicklern, Chatbots zu erstellen, die Millionen von Nutzern erreichen konnten, was eine Welle kommerziellen Interesses auslöste. Viele Unternehmen implementierten Chatbots schnell, die Ergebnisse waren jedoch gemischt. Frühe kommerzielle Implementierungen frustrierten die Nutzer oft aufgrund mangelnden Verständnisses und starrer Konversationsabläufe.
Auch die technische Architektur von Konversationssystemen entwickelte sich in dieser Zeit weiter. Der typische Ansatz umfasste eine Pipeline spezialisierter Komponenten:
Automatische Spracherkennung (für Sprachschnittstellen)
Natürliches Sprachverständnis
Dialogmanagement
Natürliche Sprachgenerierung
Text-to-Speech (für Sprachschnittstellen)
Jede Komponente konnte separat optimiert werden, was schrittweise Verbesserungen ermöglichte. Diese Pipeline-Architekturen litten jedoch manchmal unter Fehlerfortpflanzung – Fehler in frühen Phasen breiteten sich kaskadierend im gesamten System aus.
Obwohl Maschinelles Lernen die Fähigkeiten deutlich verbesserte, hatten die Systeme immer noch Schwierigkeiten, den Kontext über lange Gespräche hinweg aufrechtzuerhalten, implizite Informationen zu verstehen und wirklich vielfältige und natürliche Antworten zu generieren. Der nächste Durchbruch würde einen radikaleren Ansatz erfordern.
Die Transformer-Revolution: Neuronale Sprachmodelle
Das Jahr 2017 markierte einen Wendepunkt in der KI-Geschichte mit der Veröffentlichung von „Attention Is All You Need“ und der Einführung der Transformer-Architektur, die die Verarbeitung natürlicher Sprache revolutionieren sollte. Im Gegensatz zu früheren Ansätzen, die Text sequenziell verarbeiteten, konnten Transformers ganze Textpassagen gleichzeitig betrachten und so Beziehungen zwischen Wörtern unabhängig von deren Entfernung besser erfassen.
Diese Innovation ermöglichte die Entwicklung immer leistungsfähigerer Sprachmodelle. 2018 führte Google BERT (Bidirectional Encoder Representations from Transformers) ein, was die Leistung bei verschiedenen Sprachverständnisaufgaben deutlich verbesserte. 2019 veröffentlichte OpenAI GPT-2 und demonstrierte damit beispiellose Fähigkeiten bei der Generierung kohärenter, kontextrelevanter Texte.
Der größte Sprung erfolgte 2020 mit GPT-3, das auf 175 Milliarden Parameter skaliert werden konnte (im Vergleich zu den 1,5 Milliarden von GPT-2). Diese massive Skalierung, kombiniert mit architektonischen Verbesserungen, führte zu qualitativ unterschiedlichen Fähigkeiten. GPT-3 konnte bemerkenswert menschenähnliche Texte generieren, den Kontext über Tausende von Wörtern hinweg verstehen und sogar Aufgaben ausführen, für die es nicht explizit trainiert wurde.
Für die Konversations-KI führten diese Fortschritte zu Chatbots, die:
Kohärente Gespräche über viele Gesprächsrunden hinweg führen,
Nuancierte Anfragen ohne explizites Training verstehen,
Vielfältige, kontextbezogene Antworten generieren,
Ton und Stil an den Nutzer anpassen,
Mehrdeutigkeiten bewältigen und bei Bedarf klären konnten.
Die Veröffentlichung von ChatGPT Ende 2022 machte diese Fähigkeiten für den Mainstream zugänglich und zog innerhalb weniger Tage nach der Einführung über eine Million Nutzer an. Plötzlich hatte die breite Öffentlichkeit Zugang zu einer Konversations-KI, die sich qualitativ von allem Bisherigen unterschied – flexibler, kompetenter und natürlicher in der Interaktion.
Schnell folgten kommerzielle Implementierungen: Unternehmen integrierten große Sprachmodelle in ihre Kundenservice-Plattformen, Tools zur Inhaltserstellung und Produktivitätsanwendungen. Die schnelle Akzeptanz spiegelte sowohl den technologischen Sprung als auch die intuitive Benutzeroberfläche dieser Modelle wider – schließlich ist die Konversation für den Menschen die natürlichste Art der Kommunikation.
Diese Innovation ermöglichte die Entwicklung immer leistungsfähigerer Sprachmodelle. 2018 führte Google BERT (Bidirectional Encoder Representations from Transformers) ein, was die Leistung bei verschiedenen Sprachverständnisaufgaben deutlich verbesserte. 2019 veröffentlichte OpenAI GPT-2 und demonstrierte damit beispiellose Fähigkeiten bei der Generierung kohärenter, kontextrelevanter Texte.
Der größte Sprung erfolgte 2020 mit GPT-3, das auf 175 Milliarden Parameter skaliert werden konnte (im Vergleich zu den 1,5 Milliarden von GPT-2). Diese massive Skalierung, kombiniert mit architektonischen Verbesserungen, führte zu qualitativ unterschiedlichen Fähigkeiten. GPT-3 konnte bemerkenswert menschenähnliche Texte generieren, den Kontext über Tausende von Wörtern hinweg verstehen und sogar Aufgaben ausführen, für die es nicht explizit trainiert wurde.
Für die Konversations-KI führten diese Fortschritte zu Chatbots, die:
Kohärente Gespräche über viele Gesprächsrunden hinweg führen,
Nuancierte Anfragen ohne explizites Training verstehen,
Vielfältige, kontextbezogene Antworten generieren,
Ton und Stil an den Nutzer anpassen,
Mehrdeutigkeiten bewältigen und bei Bedarf klären konnten.
Die Veröffentlichung von ChatGPT Ende 2022 machte diese Fähigkeiten für den Mainstream zugänglich und zog innerhalb weniger Tage nach der Einführung über eine Million Nutzer an. Plötzlich hatte die breite Öffentlichkeit Zugang zu einer Konversations-KI, die sich qualitativ von allem Bisherigen unterschied – flexibler, kompetenter und natürlicher in der Interaktion.
Schnell folgten kommerzielle Implementierungen: Unternehmen integrierten große Sprachmodelle in ihre Kundenservice-Plattformen, Tools zur Inhaltserstellung und Produktivitätsanwendungen. Die schnelle Akzeptanz spiegelte sowohl den technologischen Sprung als auch die intuitive Benutzeroberfläche dieser Modelle wider – schließlich ist die Konversation für den Menschen die natürlichste Art der Kommunikation.
Testen Sie IHR Unternehmen in Minuten
Erstellen Sie Ihr Konto und starten Sie Ihren KI-Chatbot in wenigen Minuten. Vollständig anpassbar, keine Programmierung erforderlich - beginnen Sie sofort, Ihre Kunden zu begeistern!
Fertig in wenigen Minuten
Keine Programmierkenntnisse erforderlich
Multimodale Funktionen: Mehr als nur Textgespräche
Während Text die Entwicklung konversationeller KI dominiert hat, gab es in den letzten Jahren einen Trend hin zu multimodalen Systemen, die verschiedene Medientypen verstehen und generieren können. Diese Entwicklung spiegelt eine grundlegende Wahrheit menschlicher Kommunikation wider: Wir verwenden nicht nur Wörter; wir gestikulieren, zeigen Bilder, zeichnen Diagramme und nutzen unsere Umgebung, um Bedeutung zu vermitteln.
Bildsprachliche Modelle wie DALL-E, Midjourney und Stable Diffusion zeigten die Fähigkeit, Bilder aus Textbeschreibungen zu generieren, während Modelle wie GPT-4 mit visuellen Fähigkeiten Bilder analysieren und intelligent diskutieren konnten. Dies eröffnete neue Möglichkeiten für Konversationsschnittstellen:
Kundenservice-Bots, die Fotos beschädigter Produkte analysieren können
Einkaufsassistenten, die Artikel anhand von Bildern identifizieren und ähnliche Produkte finden können
Lerntools, die Diagramme und visuelle Konzepte erklären können
Barrierefreiheitsfunktionen, die Bilder für sehbehinderte Nutzer beschreiben können
Auch die Sprachfunktionen haben sich dramatisch weiterentwickelt. Frühe Sprachschnittstellen wie IVR-Systeme (Interactive Voice Response) waren notorisch frustrierend und beschränkten sich auf starre Befehle und Menüstrukturen. Moderne Sprachassistenten verstehen natürliche Sprachmuster, berücksichtigen unterschiedliche Akzente und Sprachfehler und reagieren mit immer natürlicher klingenden synthetischen Stimmen.
Die Verschmelzung dieser Fähigkeiten schafft eine wahrhaft multimodale Konversations-KI, die je nach Kontext und Nutzerbedürfnissen nahtlos zwischen verschiedenen Kommunikationsmodi wechseln kann. Ein Nutzer könnte beispielsweise zunächst eine Textfrage zur Reparatur seines Druckers stellen, ein Foto der Fehlermeldung senden, ein Diagramm mit den relevanten Schaltflächen erhalten und dann zu Sprachanweisungen wechseln, während seine Hände mit der Reparatur beschäftigt sind.
Dieser multimodale Ansatz stellt nicht nur einen technischen Fortschritt dar, sondern auch einen grundlegenden Wandel hin zu einer natürlicheren Mensch-Computer-Interaktion – die Nutzer werden in dem Kommunikationsmodus empfangen, der für ihren aktuellen Kontext und ihre Bedürfnisse am besten geeignet ist.
Bildsprachliche Modelle wie DALL-E, Midjourney und Stable Diffusion zeigten die Fähigkeit, Bilder aus Textbeschreibungen zu generieren, während Modelle wie GPT-4 mit visuellen Fähigkeiten Bilder analysieren und intelligent diskutieren konnten. Dies eröffnete neue Möglichkeiten für Konversationsschnittstellen:
Kundenservice-Bots, die Fotos beschädigter Produkte analysieren können
Einkaufsassistenten, die Artikel anhand von Bildern identifizieren und ähnliche Produkte finden können
Lerntools, die Diagramme und visuelle Konzepte erklären können
Barrierefreiheitsfunktionen, die Bilder für sehbehinderte Nutzer beschreiben können
Auch die Sprachfunktionen haben sich dramatisch weiterentwickelt. Frühe Sprachschnittstellen wie IVR-Systeme (Interactive Voice Response) waren notorisch frustrierend und beschränkten sich auf starre Befehle und Menüstrukturen. Moderne Sprachassistenten verstehen natürliche Sprachmuster, berücksichtigen unterschiedliche Akzente und Sprachfehler und reagieren mit immer natürlicher klingenden synthetischen Stimmen.
Die Verschmelzung dieser Fähigkeiten schafft eine wahrhaft multimodale Konversations-KI, die je nach Kontext und Nutzerbedürfnissen nahtlos zwischen verschiedenen Kommunikationsmodi wechseln kann. Ein Nutzer könnte beispielsweise zunächst eine Textfrage zur Reparatur seines Druckers stellen, ein Foto der Fehlermeldung senden, ein Diagramm mit den relevanten Schaltflächen erhalten und dann zu Sprachanweisungen wechseln, während seine Hände mit der Reparatur beschäftigt sind.
Dieser multimodale Ansatz stellt nicht nur einen technischen Fortschritt dar, sondern auch einen grundlegenden Wandel hin zu einer natürlicheren Mensch-Computer-Interaktion – die Nutzer werden in dem Kommunikationsmodus empfangen, der für ihren aktuellen Kontext und ihre Bedürfnisse am besten geeignet ist.
Retrieval-Augmented Generation: KI auf Fakten stützen
Trotz ihrer beeindruckenden Fähigkeiten haben große Sprachmodelle inhärente Einschränkungen. Sie können Informationen „halluzinieren“ und so plausibel klingende, aber falsche Fakten überzeugend darstellen. Ihr Wissen beschränkt sich auf die Trainingsdaten, wodurch ein Wissensklausel entsteht. Zudem können sie nicht auf Echtzeitinformationen oder spezialisierte Datenbanken zugreifen, es sei denn, sie sind speziell dafür entwickelt.
Retrieval-Augmented Generation (RAG) hat sich als Lösung für diese Herausforderungen herausgestellt. Anstatt sich ausschließlich auf im Training erlernte Parameter zu verlassen, kombinieren RAG-Systeme die generativen Fähigkeiten von Sprachmodellen mit Retrieval-Mechanismen, die auf externe Wissensquellen zugreifen können.
Die typische RAG-Architektur funktioniert folgendermaßen:
Das System empfängt eine Benutzeranfrage.
Es durchsucht relevante Wissensdatenbanken nach relevanten Informationen zur Anfrage.
Es speist sowohl die Anfrage als auch die abgerufenen Informationen in das Sprachmodell ein.
Das Modell generiert eine Antwort basierend auf den abgerufenen Fakten.
Dieser Ansatz bietet mehrere Vorteile:
Präzisere, faktenbasierte Antworten durch die Generierung auf Grundlage verifizierter Informationen.
Die Möglichkeit, über den Trainingszeitpunkt des Modells hinaus auf aktuelle Informationen zuzugreifen.
Fachwissen aus domänenspezifischen Quellen wie Unternehmensdokumenten.
Transparenz und Zuordnung durch Angabe der Informationsquellen.
Für Unternehmen, die Konversations-KI implementieren, hat sich RAG besonders für Kundenservice-Anwendungen als wertvoll erwiesen. Ein Banking-Chatbot kann beispielsweise auf die neuesten Versicherungsdokumente, Kontoinformationen und Transaktionsaufzeichnungen zugreifen, um präzise, personalisierte Antworten zu liefern, die mit einem eigenständigen Sprachmodell nicht möglich wären.
Die Entwicklung der RAG-Systeme geht weiter und umfasst Verbesserungen bei der Abrufgenauigkeit, ausgefeiltere Methoden zur Integration abgerufener Informationen in generierten Text sowie bessere Mechanismen zur Bewertung der Zuverlässigkeit verschiedener Informationsquellen.
Retrieval-Augmented Generation (RAG) hat sich als Lösung für diese Herausforderungen herausgestellt. Anstatt sich ausschließlich auf im Training erlernte Parameter zu verlassen, kombinieren RAG-Systeme die generativen Fähigkeiten von Sprachmodellen mit Retrieval-Mechanismen, die auf externe Wissensquellen zugreifen können.
Die typische RAG-Architektur funktioniert folgendermaßen:
Das System empfängt eine Benutzeranfrage.
Es durchsucht relevante Wissensdatenbanken nach relevanten Informationen zur Anfrage.
Es speist sowohl die Anfrage als auch die abgerufenen Informationen in das Sprachmodell ein.
Das Modell generiert eine Antwort basierend auf den abgerufenen Fakten.
Dieser Ansatz bietet mehrere Vorteile:
Präzisere, faktenbasierte Antworten durch die Generierung auf Grundlage verifizierter Informationen.
Die Möglichkeit, über den Trainingszeitpunkt des Modells hinaus auf aktuelle Informationen zuzugreifen.
Fachwissen aus domänenspezifischen Quellen wie Unternehmensdokumenten.
Transparenz und Zuordnung durch Angabe der Informationsquellen.
Für Unternehmen, die Konversations-KI implementieren, hat sich RAG besonders für Kundenservice-Anwendungen als wertvoll erwiesen. Ein Banking-Chatbot kann beispielsweise auf die neuesten Versicherungsdokumente, Kontoinformationen und Transaktionsaufzeichnungen zugreifen, um präzise, personalisierte Antworten zu liefern, die mit einem eigenständigen Sprachmodell nicht möglich wären.
Die Entwicklung der RAG-Systeme geht weiter und umfasst Verbesserungen bei der Abrufgenauigkeit, ausgefeiltere Methoden zur Integration abgerufener Informationen in generierten Text sowie bessere Mechanismen zur Bewertung der Zuverlässigkeit verschiedener Informationsquellen.
Das Mensch-KI-Kollaborationsmodell: Die richtige Balance finden
Mit der Erweiterung der Möglichkeiten der Konversations-KI hat sich auch die Beziehung zwischen Mensch und KI-Systemen weiterentwickelt. Frühe Chatbots waren eindeutig als Werkzeuge positioniert – begrenzt in ihrem Umfang und offensichtlich nicht-menschlich in ihren Interaktionen. Moderne Systeme verwischen diese Grenzen und werfen neue Fragen zur Gestaltung einer effektiven Mensch-KI-Zusammenarbeit auf.
Die erfolgreichsten Implementierungen folgen heute einem kollaborativen Modell, bei dem:
Die KI bearbeitet routinemäßige, sich wiederholende Anfragen, die kein menschliches Urteilsvermögen erfordern.
Menschen konzentrieren sich auf komplexe Fälle, die Empathie, ethisches Denken oder kreative Problemlösungen erfordern.
Das System kennt seine Grenzen und leitet die Anfragen bei Bedarf nahtlos an menschliche Mitarbeiter weiter.
Der Übergang zwischen KI und menschlicher Unterstützung ist für den Nutzer nahtlos.
Menschliche Mitarbeiter haben den vollständigen Kontext des Gesprächsverlaufs mit der KI.
KI lernt kontinuierlich aus menschlichen Eingriffen und erweitert so schrittweise ihre Fähigkeiten.
Dieser Ansatz trägt dem Ziel Rechnung, dass Konversations-KI die menschliche Interaktion nicht vollständig ersetzen, sondern ergänzen sollte – indem sie die umfangreichen, unkomplizierten Anfragen bearbeitet, die menschliche Mitarbeiter zeitaufwendig machen, und gleichzeitig sicherstellt, dass komplexe Probleme die richtige menschliche Expertise erreichen.
Die Umsetzung dieses Modells variiert branchenübergreifend. Im Gesundheitswesen könnten KI-Chatbots die Terminplanung und das grundlegende Symptomscreening übernehmen und gleichzeitig sicherstellen, dass medizinische Beratung von qualifiziertem Fachpersonal erfolgt. In der Rechtsberatung könnte KI bei der Dokumentenerstellung und -recherche helfen, während die Interpretation und Strategie den Anwälten überlassen bleibt. Im Kundenservice kann KI allgemeine Probleme lösen und komplexe Probleme an spezialisierte Mitarbeiter weiterleiten.
Mit der Weiterentwicklung der KI-Fähigkeiten verschiebt sich die Grenze zwischen dem, was menschliches Eingreifen erfordert und dem, was automatisiert werden kann. Das Grundprinzip bleibt jedoch bestehen: Effektive Konversations-KI sollte menschliche Fähigkeiten erweitern, anstatt sie einfach zu ersetzen.
Die erfolgreichsten Implementierungen folgen heute einem kollaborativen Modell, bei dem:
Die KI bearbeitet routinemäßige, sich wiederholende Anfragen, die kein menschliches Urteilsvermögen erfordern.
Menschen konzentrieren sich auf komplexe Fälle, die Empathie, ethisches Denken oder kreative Problemlösungen erfordern.
Das System kennt seine Grenzen und leitet die Anfragen bei Bedarf nahtlos an menschliche Mitarbeiter weiter.
Der Übergang zwischen KI und menschlicher Unterstützung ist für den Nutzer nahtlos.
Menschliche Mitarbeiter haben den vollständigen Kontext des Gesprächsverlaufs mit der KI.
KI lernt kontinuierlich aus menschlichen Eingriffen und erweitert so schrittweise ihre Fähigkeiten.
Dieser Ansatz trägt dem Ziel Rechnung, dass Konversations-KI die menschliche Interaktion nicht vollständig ersetzen, sondern ergänzen sollte – indem sie die umfangreichen, unkomplizierten Anfragen bearbeitet, die menschliche Mitarbeiter zeitaufwendig machen, und gleichzeitig sicherstellt, dass komplexe Probleme die richtige menschliche Expertise erreichen.
Die Umsetzung dieses Modells variiert branchenübergreifend. Im Gesundheitswesen könnten KI-Chatbots die Terminplanung und das grundlegende Symptomscreening übernehmen und gleichzeitig sicherstellen, dass medizinische Beratung von qualifiziertem Fachpersonal erfolgt. In der Rechtsberatung könnte KI bei der Dokumentenerstellung und -recherche helfen, während die Interpretation und Strategie den Anwälten überlassen bleibt. Im Kundenservice kann KI allgemeine Probleme lösen und komplexe Probleme an spezialisierte Mitarbeiter weiterleiten.
Mit der Weiterentwicklung der KI-Fähigkeiten verschiebt sich die Grenze zwischen dem, was menschliches Eingreifen erfordert und dem, was automatisiert werden kann. Das Grundprinzip bleibt jedoch bestehen: Effektive Konversations-KI sollte menschliche Fähigkeiten erweitern, anstatt sie einfach zu ersetzen.
Die Zukunftslandschaft: Wohin sich Conversational AI entwickelt
Mit Blick auf die Zukunft prägen verschiedene neue Trends die Zukunft der Konversations-KI. Diese Entwicklungen versprechen nicht nur schrittweise Verbesserungen, sondern potenziell tiefgreifende Veränderungen in unserem Umgang mit Technologie.
Personalisierung im großen Maßstab: Zukünftige Systeme werden ihre Antworten zunehmend nicht nur auf den unmittelbaren Kontext, sondern auch auf den Kommunikationsstil, die Präferenzen, den Wissensstand und die Beziehungshistorie jedes Nutzers zuschneiden. Diese Personalisierung wird Interaktionen natürlicher und relevanter machen, wirft aber wichtige Fragen zu Datenschutz und Datennutzung auf.
Emotionale Intelligenz: Während heutige Systeme grundlegende Stimmungen erkennen können, wird zukünftige Konversations-KI eine ausgefeiltere emotionale Intelligenz entwickeln – sie erkennt subtile Gefühlszustände, reagiert angemessen auf Stress oder Frustration und passt Ton und Vorgehensweise entsprechend an. Diese Fähigkeit wird besonders im Kundenservice, im Gesundheitswesen und im Bildungsbereich wertvoll sein.
Proaktive Unterstützung: Anstatt auf explizite Anfragen zu warten, antizipieren Konversationssysteme der nächsten Generation Bedürfnisse anhand von Kontext, Nutzerhistorie und Umgebungssignalen. Ein System könnte beispielsweise bemerken, dass Sie mehrere Meetings in einer unbekannten Stadt planen, und proaktiv Transportoptionen oder Wettervorhersagen anbieten.
Nahtlose multimodale Integration: Zukünftige Systeme werden nicht nur verschiedene Modalitäten unterstützen, sondern diese nahtlos integrieren. Eine Konversation könnte ganz natürlich zwischen Text, Sprache, Bildern und interaktiven Elementen fließen und für jede Information die passende Modalität wählen, ohne dass der Nutzer explizit eine Auswahl treffen muss.
Spezialisierte Fachexperten: Während sich allgemeine Assistenten weiter verbessern, werden wir auch den Aufstieg hochspezialisierter Konversations-KI mit tiefgreifender Expertise in bestimmten Bereichen erleben – Rechtsassistenten, die sich mit Rechtsprechung und Präzedenzfällen auskennen, medizinische Systeme mit umfassendem Wissen über Arzneimittelwechselwirkungen und Behandlungsprotokolle oder Finanzberater, die sich mit Steuerrecht und Anlagestrategien auskennen.
Kontinuierliches Lernen: Zukünftige Systeme werden über regelmäßiges Retraining hinausgehen und kontinuierlich aus Interaktionen lernen. Sie werden mit der Zeit hilfreicher und personalisierter werden und gleichzeitig angemessene Datenschutzvorkehrungen gewährleisten.
Trotz dieser spannenden Möglichkeiten bleiben Herausforderungen bestehen. Datenschutzbedenken, die Vermeidung von Vorurteilen, angemessene Transparenz und die Schaffung eines angemessenen Maßes an menschlicher Kontrolle sind anhaltende Themen, die sowohl die Technologie als auch ihre Regulierung prägen werden. Die erfolgreichsten Implementierungen werden diejenigen sein, die diese Herausforderungen sorgfältig angehen und gleichzeitig einen echten Mehrwert für die Nutzer bieten.
Klar ist: Konversations-KI hat sich von einer Nischentechnologie zu einem etablierten Schnittstellenparadigma entwickelt, das unsere Interaktion mit digitalen Systemen zunehmend prägen wird. Der evolutionäre Weg vom einfachen Mustervergleich von ELIZA zu den heutigen komplexen Sprachmodellen stellt einen der bedeutendsten Fortschritte in der Mensch-Computer-Interaktion dar – und die Reise ist noch lange nicht zu Ende.
Personalisierung im großen Maßstab: Zukünftige Systeme werden ihre Antworten zunehmend nicht nur auf den unmittelbaren Kontext, sondern auch auf den Kommunikationsstil, die Präferenzen, den Wissensstand und die Beziehungshistorie jedes Nutzers zuschneiden. Diese Personalisierung wird Interaktionen natürlicher und relevanter machen, wirft aber wichtige Fragen zu Datenschutz und Datennutzung auf.
Emotionale Intelligenz: Während heutige Systeme grundlegende Stimmungen erkennen können, wird zukünftige Konversations-KI eine ausgefeiltere emotionale Intelligenz entwickeln – sie erkennt subtile Gefühlszustände, reagiert angemessen auf Stress oder Frustration und passt Ton und Vorgehensweise entsprechend an. Diese Fähigkeit wird besonders im Kundenservice, im Gesundheitswesen und im Bildungsbereich wertvoll sein.
Proaktive Unterstützung: Anstatt auf explizite Anfragen zu warten, antizipieren Konversationssysteme der nächsten Generation Bedürfnisse anhand von Kontext, Nutzerhistorie und Umgebungssignalen. Ein System könnte beispielsweise bemerken, dass Sie mehrere Meetings in einer unbekannten Stadt planen, und proaktiv Transportoptionen oder Wettervorhersagen anbieten.
Nahtlose multimodale Integration: Zukünftige Systeme werden nicht nur verschiedene Modalitäten unterstützen, sondern diese nahtlos integrieren. Eine Konversation könnte ganz natürlich zwischen Text, Sprache, Bildern und interaktiven Elementen fließen und für jede Information die passende Modalität wählen, ohne dass der Nutzer explizit eine Auswahl treffen muss.
Spezialisierte Fachexperten: Während sich allgemeine Assistenten weiter verbessern, werden wir auch den Aufstieg hochspezialisierter Konversations-KI mit tiefgreifender Expertise in bestimmten Bereichen erleben – Rechtsassistenten, die sich mit Rechtsprechung und Präzedenzfällen auskennen, medizinische Systeme mit umfassendem Wissen über Arzneimittelwechselwirkungen und Behandlungsprotokolle oder Finanzberater, die sich mit Steuerrecht und Anlagestrategien auskennen.
Kontinuierliches Lernen: Zukünftige Systeme werden über regelmäßiges Retraining hinausgehen und kontinuierlich aus Interaktionen lernen. Sie werden mit der Zeit hilfreicher und personalisierter werden und gleichzeitig angemessene Datenschutzvorkehrungen gewährleisten.
Trotz dieser spannenden Möglichkeiten bleiben Herausforderungen bestehen. Datenschutzbedenken, die Vermeidung von Vorurteilen, angemessene Transparenz und die Schaffung eines angemessenen Maßes an menschlicher Kontrolle sind anhaltende Themen, die sowohl die Technologie als auch ihre Regulierung prägen werden. Die erfolgreichsten Implementierungen werden diejenigen sein, die diese Herausforderungen sorgfältig angehen und gleichzeitig einen echten Mehrwert für die Nutzer bieten.
Klar ist: Konversations-KI hat sich von einer Nischentechnologie zu einem etablierten Schnittstellenparadigma entwickelt, das unsere Interaktion mit digitalen Systemen zunehmend prägen wird. Der evolutionäre Weg vom einfachen Mustervergleich von ELIZA zu den heutigen komplexen Sprachmodellen stellt einen der bedeutendsten Fortschritte in der Mensch-Computer-Interaktion dar – und die Reise ist noch lange nicht zu Ende.





